Model Intelligence Sheet
mungert/typhoon-ocr-7b-gguf overview
Comprehensive model page for mungert/typhoon-ocr-7b-gguf
Downloads
301
Likes
0
Pipeline
—
Library
transformers
Visibility
Public
Access
Open
Repository Files & Downloads
27 files detected
Direct downloads for all repository files
| File | Type | Quantization | Size | Link |
|---|---|---|---|---|
| typhoon-ocr-7b-bf16.gguf | GGUF | BF16 | 14.19 GB | Download |
| typhoon-ocr-7b-bf16_q8_0.gguf | GGUF | BF16 | 8.49 GB | Download |
| typhoon-ocr-7b-f16_q8_0.gguf | GGUF | F16 | 10.51 GB | Download |
| typhoon-ocr-7b-iq2_m.gguf | GGUF | IQ2_M | 2.83 GB | Download |
| typhoon-ocr-7b-iq2_s.gguf | GGUF | IQ2_S | 2.71 GB | Download |
| typhoon-ocr-7b-iq2_xs.gguf | GGUF | IQ2_XS | 2.64 GB | Download |
| typhoon-ocr-7b-iq2_xxs.gguf | GGUF | IQ2_XXS | 2.47 GB | Download |
| typhoon-ocr-7b-iq3_m.gguf | GGUF | IQ3_M | 3.36 GB | Download |
| typhoon-ocr-7b-iq3_s.gguf | GGUF | IQ3_S | 3.32 GB | Download |
| typhoon-ocr-7b-iq3_xs.gguf | GGUF | IQ3_XS | 3.18 GB | Download |
| typhoon-ocr-7b-iq3_xxs.gguf | GGUF | IQ3_XXS | 3.05 GB | Download |
| typhoon-ocr-7b-iq4_nl.gguf | GGUF | IQ4_NL | 4.13 GB | Download |
| typhoon-ocr-7b-iq4_xs.gguf | GGUF | IQ4_XS | 3.93 GB | Download |
| typhoon-ocr-7b-q2_k_m.gguf | GGUF | Q2_K_M | 3.04 GB | Download |
| typhoon-ocr-7b-q2_k_s.gguf | GGUF | Q2_K_S | 2.73 GB | Download |
| typhoon-ocr-7b-q3_k_m.gguf | GGUF | Q3_K_M | 3.72 GB | Download |
| typhoon-ocr-7b-q3_k_s.gguf | GGUF | Q3_K_S | 3.36 GB | Download |
| typhoon-ocr-7b-q4_0.gguf | GGUF | — | 4.00 GB | Download |
| typhoon-ocr-7b-q4_1.gguf | GGUF | — | 4.44 GB | Download |
| typhoon-ocr-7b-q4_k_m.gguf | GGUF | Q4_K_M | 4.45 GB | Download |
| typhoon-ocr-7b-q4_k_s.gguf | GGUF | Q4_K_S | 4.32 GB | Download |
| typhoon-ocr-7b-q5_0.gguf | GGUF | — | 4.88 GB | Download |
| typhoon-ocr-7b-q5_1.gguf | GGUF | — | 5.33 GB | Download |
| typhoon-ocr-7b-q5_k_m.gguf | GGUF | Q5_K_M | 5.15 GB | Download |
| typhoon-ocr-7b-q5_k_s.gguf | GGUF | Q5_K_S | 5.08 GB | Download |
| typhoon-ocr-7b-q6_k_m.gguf | GGUF | Q6_K_M | 5.82 GB | Download |
| typhoon-ocr-7b-q8_0.gguf | GGUF | — | 7.54 GB | Download |
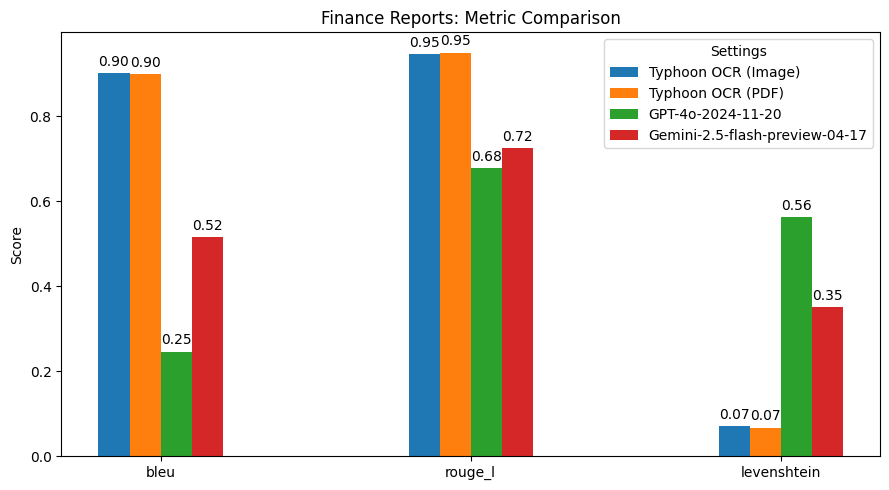
Model Details Live
Metadata Inspector
Normalized metadata (stored in metadata_json)
{
"metadata": {},
"card_data": {
"library_name": "transformers",
"language": [
"en",
"th"
],
"base_model": [
"Qwen/Qwen2.5-VL-7B-Instruct"
],
"tags": [
"OCR",
"vision-language",
"document-understanding",
"multilingual"
],
"license": "apache-2.0",
"frontmatter": {
"library_name": "transformers",
"language": [
"en",
"th"
],
"base_model": [
"Qwen/Qwen2.5-VL-7B-Instruct"
],
"tags": [
"OCR",
"vision-language",
"document-understanding",
"multilingual"
],
"license": "apache-2.0"
},
"hero_image_url": "https://storage.googleapis.com/typhoon-public/assets/typhoon_ocr/eval_finance.png",
"summary": "",
"quick_links": [],
"benchmark_table_html": "",
"readme_markdown": "---\nlibrary_name: transformers\nlanguage:\n- en\n- th\nbase_model:\n- Qwen/Qwen2.5-VL-7B-Instruct\ntags:\n- OCR\n- vision-language\n- document-understanding\n- multilingual\nlicense: apache-2.0\n---\n\n# <span style=\"color: #7FFF7F;\">typhoon-ocr-7b GGUF Models</span>\n\n\n## <span style=\"color: #7F7FFF;\">Model Generation Details</span>\n\nThis model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`92ecdcc0`](https://github.com/ggerganov/llama.cpp/commit/92ecdcc06a4c405a415bcaa0cb772bc560aa23b1).\n\n\n\n\n## <span style=\"color: #7FFF7F;\">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>\n\nOur latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.\n\n### **Benchmark Context**\nAll tests conducted on **Llama-3-8B-Instruct** using:\n- Standard perplexity evaluation pipeline\n- 2048-token context window\n- Same prompt set across all quantizations\n\n### **Method**\n- **Dynamic Precision Allocation**: \n - First/Last 25% of layers → IQ4_XS (selected layers) \n - Middle 50% → IQ2_XXS/IQ3_S (increase efficiency) \n- **Critical Component Protection**: \n - Embeddings/output layers use Q5_K \n - Reduces error propagation by 38% vs standard 1-2bit \n\n### **Quantization Performance Comparison (Llama-3-8B)**\n\n| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |\n|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|\n| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |\n| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |\n| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |\n| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |\n| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |\n\n**Key**:\n- PPL = Perplexity (lower is better)\n- Δ PPL = Percentage change from standard to DynamicGate\n- Speed = Inference time (CPU avx2, 2048 token context)\n- Size differences reflect mixed quantization overhead\n\n**Key Improvements:**\n- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)\n- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB\n- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization\n\n**Tradeoffs:**\n- All variants have modest size increases (0.1-0.3GB)\n- Inference speeds remain comparable (<5% difference)\n\n\n### **When to Use These Models**\n📌 **Fitting models into GPU VRAM**\n\n✔ **Memory-constrained deployments**\n\n✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated \n \n✔ **Research** into ultra-low-bit quantization\n\n\n\n## **Choosing the Right Model Format** \n\nSelecting the correct model format depends on your **hardware capabilities** and **memory constraints**. \n\n### **BF16 (Brain Float 16) – Use if BF16 acceleration is available** \n- A 16-bit floating-point format designed for **faster computation** while retaining good precision. \n- Provides **similar dynamic range** as FP32 but with **lower memory usage**. \n- Recommended if your hardware supports **BF16 acceleration** (check your device's specs). \n- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32. \n\n📌 **Use BF16 if:** \n✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs). \n✔ You want **higher precision** while saving memory. \n✔ You plan to **requantize** the model into another format. \n\n📌 **Avoid BF16 if:** \n❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower). \n❌ You need compatibility with older devices that lack BF16 optimization. \n\n---\n\n### **F16 (Float 16) – More widely supported than BF16** \n- A 16-bit floating-point **high precision** but with less of range of values than BF16. \n- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs). \n- Slightly lower numerical precision than BF16 but generally sufficient for inference. \n\n📌 **Use F16 if:** \n✔ Your hardware supports **FP16** but **not BF16**. \n✔ You need a **balance between speed, memory usage, and accuracy**. \n✔ You are running on a **GPU** or another device optimized for FP16 computations. \n\n📌 **Avoid F16 if:** \n❌ Your device lacks **native FP16 support** (it may run slower than expected). \n❌ You have memory limitations. \n\n---\n\n### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference** \nQuantization reduces model size and memory usage while maintaining as much accuracy as possible. \n- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision. \n- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory. \n\n📌 **Use Quantized Models if:** \n✔ You are running inference on a **CPU** and need an optimized model. \n✔ Your device has **low VRAM** and cannot load full-precision models. \n✔ You want to reduce **memory footprint** while keeping reasonable accuracy. \n\n📌 **Avoid Quantized Models if:** \n❌ You need **maximum accuracy** (full-precision models are better for this). \n❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16). \n\n---\n\n### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)** \nThese models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint. \n\n- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**. \n - **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large. \n - **Trade-off**: Lower accuracy compared to higher-bit quantizations. \n\n- **IQ3_S**: Small block size for **maximum memory efficiency**. \n - **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive. \n\n- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**. \n - **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting. \n\n- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy. \n - **Use case**: Best for **low-memory devices** where **Q6_K** is too large. \n\n- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**. \n - **Use case**: Best for **ARM-based devices** or **low-memory environments**. \n\n---\n\n### **Summary Table: Model Format Selection** \n\n| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case | \n|--------------|------------|---------------|----------------------|---------------| \n| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory | \n| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available | \n| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments | \n| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized | \n| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models | \n| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy | \n| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices | \n\n---\n\n## **Included Files & Details** \n\n### `typhoon-ocr-7b-bf16.gguf` \n- Model weights preserved in **BF16**. \n- Use this if you want to **requantize** the model into a different format. \n- Best if your device supports **BF16 acceleration**. \n\n### `typhoon-ocr-7b-f16.gguf` \n- Model weights stored in **F16**. \n- Use if your device supports **FP16**, especially if BF16 is not available. \n\n### `typhoon-ocr-7b-bf16-q8_0.gguf` \n- **Output & embeddings** remain in **BF16**. \n- All other layers quantized to **Q8_0**. \n- Use if your device supports **BF16** and you want a quantized version. \n\n### `typhoon-ocr-7b-f16-q8_0.gguf` \n- **Output & embeddings** remain in **F16**. \n- All other layers quantized to **Q8_0**. \n\n### `typhoon-ocr-7b-q4_k.gguf` \n- **Output & embeddings** quantized to **Q8_0**. \n- All other layers quantized to **Q4_K**. \n- Good for **CPU inference** with limited memory. \n\n### `typhoon-ocr-7b-q4_k_s.gguf` \n- Smallest **Q4_K** variant, using less memory at the cost of accuracy. \n- Best for **very low-memory setups**. \n\n### `typhoon-ocr-7b-q6_k.gguf` \n- **Output & embeddings** quantized to **Q8_0**. \n- All other layers quantized to **Q6_K** . \n\n### `typhoon-ocr-7b-q8_0.gguf` \n- Fully **Q8** quantized model for better accuracy. \n- Requires **more memory** but offers higher precision. \n\n### `typhoon-ocr-7b-iq3_xs.gguf` \n- **IQ3_XS** quantization, optimized for **extreme memory efficiency**. \n- Best for **ultra-low-memory devices**. \n\n### `typhoon-ocr-7b-iq3_m.gguf` \n- **IQ3_M** quantization, offering a **medium block size** for better accuracy. \n- Suitable for **low-memory devices**. \n\n### `typhoon-ocr-7b-q4_0.gguf` \n- Pure **Q4_0** quantization, optimized for **ARM devices**. \n- Best for **low-memory environments**.\n- Prefer IQ4_NL for better accuracy.\n\n# <span id=\"testllm\" style=\"color: #7F7FFF;\">🚀 If you find these models useful</span>\n❤ **Please click \"Like\" if you find this useful!** \nHelp me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**: \n👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) \n\n💬 **How to test**: \n Choose an **AI assistant type**: \n - `TurboLLM` (GPT-4o-mini) \n - `HugLLM` (Hugginface Open-source) \n - `TestLLM` (Experimental CPU-only) \n\n### **What I’m Testing** \nI’m pushing the limits of **small open-source models for AI network monitoring**, specifically: \n- **Function calling** against live network services \n- **How small can a model go** while still handling: \n - Automated **Nmap scans** \n - **Quantum-readiness checks** \n - **Network Monitoring tasks** \n\n🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads): \n- ✅ **Zero-configuration setup** \n- ⏳ 30s load time (slow inference but **no API costs**) \n- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate! \n\n### **Other Assistants** \n🟢 **TurboLLM** – Uses **gpt-4o-mini** for: \n- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**\n- **Real-time network diagnostics and monitoring**\n- **Security Audits**\n- **Penetration testing** (Nmap/Metasploit) \n \n\n🔵 **HugLLM** – Latest Open-source models: \n- 🌐 Runs on Hugging Face Inference API \n\n### 💡 **Example commands to you could test**: \n1. `\"Give me info on my websites SSL certificate\"` \n2. `\"Check if my server is using quantum safe encyption for communication\"` \n3. `\"Run a comprehensive security audit on my server\"`\n4. '\"Create a cmd processor to .. (what ever you want)\" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!\n\n### Final Word\n\nI fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.\n\nIf you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.\n\nI'm also open to job opportunities or sponsorship.\n\nThank you! 😊\n\n\n\n\n\n\n**Typhoon-OCR-7B**: A bilingual document parsing model built specifically for real-world documents in Thai and English inspired by models like olmOCR based on Qwen2.5-VL-Instruction.\n\n**Try our demo available on [Demo](https://ocr.opentyphoon.ai/)**\n\n**Code / Examples available on [Github](https://github.com/scb-10x/typhoon-ocr)**\n\n**Release Blog available on [OpenTyphoon Blog](https://opentyphoon.ai/blog/en/typhoon-ocr-release)**\n\n*Remark: This model is intended to be used with a specific prompt only; it will not work with any other prompts.\n\n\n## **Real-World Document Support**\n\n**1. Structured Documents**: Financial reports, Academic papers, Books, Government forms\n\n**Output format**:\n- Markdown for general text\n- HTML for tables (including merged cells and complex layouts)\n- Figures, charts, and diagrams are represented using figure tags for structured visual understanding\n\n**Each figure undergoes multi-layered interpretation**:\n- **Observation**: Detects elements like landscapes, buildings, people, logos, and embedded text\n- **Context Analysis**: Infers context such as location, event, or document section\n- **Text Recognition**: Extracts and interprets embedded text (e.g., chart labels, captions) in Thai or English\n- **Artistic & Structural Analysis**: Captures layout style, diagram type, or design choices contributing to document tone\n- **Final Summary**: Combines all insights into a structured figure description for tasks like summarization and retrieval\n\n\n**2. Layout-Heavy & Informal Documents**: Receipts, Menus papers, Tickets, Infographics\n\n**Output format**:\n- Markdown with embedded tables and layout-aware structures\n\n## Performance\n\n\n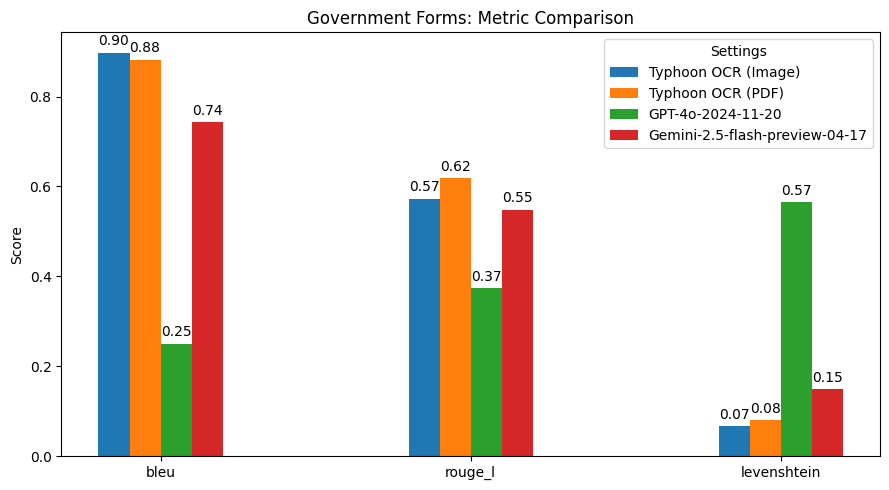\n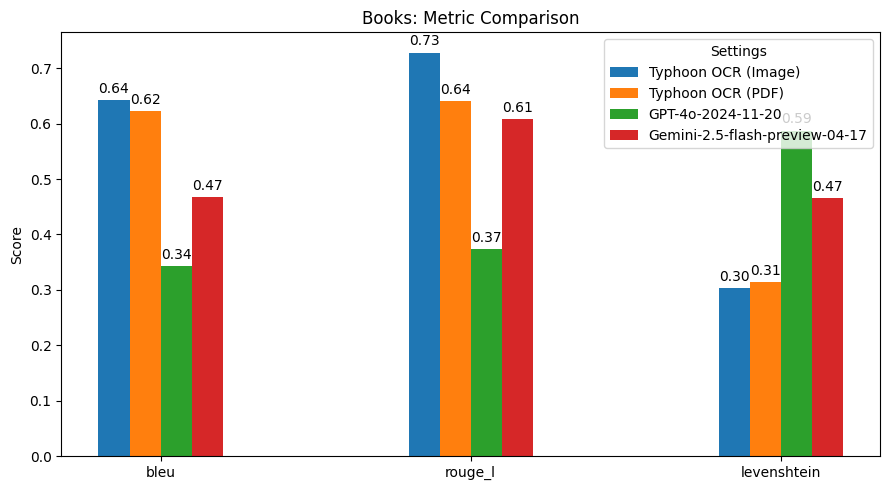\n\n\n## Summary of Findings\n\nTyphoon OCR outperforms both GPT-4o and Gemini 2.5 Flash in Thai document understanding, particularly on documents with complex layouts and mixed-language content.\nHowever, in the Thai books benchmark, performance slightly declined due to the high frequency and diversity of embedded figures. These images vary significantly in type and structure, which poses challenges for our current figure tag parsing. This highlights a potential area for future improvement—specifically, in enhancing the model's image understanding capabilities.\nFor this version, our primary focus has been on achieving high-quality OCR for both English and Thai text. Future releases may extend support to more advanced image analysis and figure interpretation.\n\n## Usage Example\n\n**(Recommended): Full inference code available on [Colab](https://colab.research.google.com/drive/1z4Fm2BZnKcFIoWuyxzzIIIn8oI2GKl3r?usp=sharing)**\n\n\n**(Recommended): Using Typhoon-OCR Package**\n```bash\npip install typhoon-ocr\n```\n\n```python\nfrom typhoon_ocr import ocr_document\n\n# please set env TYPHOON_OCR_API_KEY or OPENAI_API_KEY to use this function\nmarkdown = ocr_document(\"test.png\")\nprint(markdown)\n```\n**Run Manually**\n\nBelow is a partial snippet. You can run inference using either the API or a local model.\n\n*API*:\n```python\nfrom typing import Callable\nfrom openai import OpenAI\nfrom PIL import Image\nfrom typhoon_ocr.ocr_utils import render_pdf_to_base64png, get_anchor_text\n\nPROMPTS_SYS = {\n \"default\": lambda base_text: (f\"Below is an image of a document page along with its dimensions. \"\n f\"Simply return the markdown representation of this document, presenting tables in markdown format as they naturally appear.\\n\"\n f\"If the document contains images, use a placeholder like dummy.png for each image.\\n\"\n f\"Your final output must be in JSON format with a single key `natural_text` containing the response.\\n\"\n f\"RAW_TEXT_START\\n{base_text}\\nRAW_TEXT_END\"),\n \"structure\": lambda base_text: (\n f\"Below is an image of a document page, along with its dimensions and possibly some raw textual content previously extracted from it. \"\n f\"Note that the text extraction may be incomplete or partially missing. Carefully consider both the layout and any available text to reconstruct the document accurately.\\n\"\n f\"Your task is to return the markdown representation of this document, presenting tables in HTML format as they naturally appear.\\n\"\n f\"If the document contains images or figures, analyze them and include the tag <figure>IMAGE_ANALYSIS</figure> in the appropriate location.\\n\"\n f\"Your final output must be in JSON format with a single key `natural_text` containing the response.\\n\"\n f\"RAW_TEXT_START\\n{base_text}\\nRAW_TEXT_END\"\n ),\n}\n\ndef get_prompt(prompt_name: str) -> Callable[[str], str]:\n \"\"\"\n Fetches the system prompt based on the provided PROMPT_NAME.\n\n :param prompt_name: The identifier for the desired prompt.\n :return: The system prompt as a string.\n \"\"\"\n return PROMPTS_SYS.get(prompt_name, lambda x: \"Invalid PROMPT_NAME provided.\")\n\n\n\n# Render the first page to base64 PNG and then load it into a PIL image.\nimage_base64 = render_pdf_to_base64png(filename, page_num, target_longest_image_dim=1800)\nimage_pil = Image.open(BytesIO(base64.b64decode(image_base64)))\n\n# Extract anchor text from the PDF (first page)\nanchor_text = get_anchor_text(filename, page_num, pdf_engine=\"pdfreport\", target_length=8000)\n\n# Retrieve and fill in the prompt template with the anchor_text\nprompt_template_fn = get_prompt(task_type)\nPROMPT = prompt_template_fn(anchor_text)\n\nmessages = [{\n \"role\": \"user\",\n \"content\": [\n {\"type\": \"text\", \"text\": PROMPT},\n {\"type\": \"image_url\", \"image_url\": {\"url\": f\"data:image/png;base64,{image_base64}\"}},\n ],\n }]\n# send messages to openai compatible api\nopenai = OpenAI(base_url=\"https://api.opentyphoon.ai/v1\", api_key=\"TYPHOON_API_KEY\")\nresponse = openai.chat.completions.create(\n model=\"typhoon-ocr-preview\",\n messages=messages,\n max_tokens=16384,\n temperature=0.1,\n top_p=0.6,\n extra_body={\n \"repetition_penalty\": 1.2,\n },\n )\ntext_output = response.choices[0].message.content\nprint(text_output)\n```\n*Local Model (GPU Required)*:\n```python\n# Initialize the model\nmodel = Qwen2_5_VLForConditionalGeneration.from_pretrained(\"scb10x/typhoon-ocr-7b\", torch_dtype=torch.bfloat16 ).eval()\nprocessor = AutoProcessor.from_pretrained(\"scb10x/typhoon-ocr-7b\")\n\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nmodel.to(device)\n# Apply the chat template and processor\ntext = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)\nmain_image = Image.open(BytesIO(base64.b64decode(image_base64)))\n\ninputs = processor(\n text=[text],\n images=[main_image],\n padding=True,\n return_tensors=\"pt\",\n )\ninputs = {key: value.to(device) for (key, value) in inputs.items()}\n\n# Generate the output\noutput = model.generate(\n **inputs,\n temperature=0.1,\n max_new_tokens=12000,\n num_return_sequences=1,\n repetition_penalty=1.2,\n do_sample=True,\n )\n# Decode the output\nprompt_length = inputs[\"input_ids\"].shape[1]\nnew_tokens = output[:, prompt_length:]\ntext_output = processor.tokenizer.batch_decode(\n new_tokens, skip_special_tokens=True\n )\nprint(text_output[0])\n```\n\n## Prompting\n\nThis model only works with the specific prompts defined below, where `{base_text}` refers to information extracted from the PDF metadata using the `get_anchor_text` function from the `typhoon-ocr` package. It will not function correctly with any other prompts.\n\n```\nPROMPTS_SYS = {\n \"default\": lambda base_text: (f\"Below is an image of a document page along with its dimensions. \"\n f\"Simply return the markdown representation of this document, presenting tables in markdown format as they naturally appear.\\n\"\n f\"If the document contains images, use a placeholder like dummy.png for each image.\\n\"\n f\"Your final output must be in JSON format with a single key `natural_text` containing the response.\\n\"\n f\"RAW_TEXT_START\\n{base_text}\\nRAW_TEXT_END\"),\n \"structure\": lambda base_text: (\n f\"Below is an image of a document page, along with its dimensions and possibly some raw textual content previously extracted from it. \"\n f\"Note that the text extraction may be incomplete or partially missing. Carefully consider both the layout and any available text to reconstruct the document accurately.\\n\"\n f\"Your task is to return the markdown representation of this document, presenting tables in HTML format as they naturally appear.\\n\"\n f\"If the document contains images or figures, analyze them and include the tag <figure>IMAGE_ANALYSIS</figure> in the appropriate location.\\n\"\n f\"Your final output must be in JSON format with a single key `natural_text` containing the response.\\n\"\n f\"RAW_TEXT_START\\n{base_text}\\nRAW_TEXT_END\"\n ),\n}\n```\n\n### Generation Parameters\n\nWe suggest using the following generation parameters. Since this is an OCR model, we do not recommend using a high temperature. Make sure the temperature is set to 0 or 0.1, not higher.\n```\ntemperature=0.1,\ntop_p=0.6,\nrepetition_penalty: 1.2\n```\n\n## **Intended Uses & Limitations**\n\nThis is a task-specific model intended to be used only with the provided prompts. It does not include any guardrails or VQA capability. Due to the nature of large language models (LLMs), a certain level of hallucination may occur. We recommend that developers carefully assess these risks in the context of their specific use case.\n\n## **Follow us**\n\n**https://twitter.com/opentyphoon**\n\n## **Support**\n\n**https://discord.gg/us5gAYmrxw**\n\n\n## **Citation**\n\n- If you find Typhoon2 useful for your work, please cite it using:\n```\n@misc{typhoon2,\n title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models}, \n author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},\n year={2024},\n eprint={2412.13702},\n archivePrefix={arXiv},\n primaryClass={cs.CL},\n url={https://arxiv.org/abs/2412.13702}, \n}\n```",
"related_quantizations": []
},
"tags": [
"transformers",
"gguf",
"OCR",
"vision-language",
"document-understanding",
"multilingual",
"en",
"th",
"arxiv:2412.13702",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-7B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
],
"likes": 0,
"downloads": 301,
"gated": false,
"private": false,
"last_modified": "2025-09-24T15:42:31.000Z",
"created_at": "2025-05-22T02:20:38.000Z",
"pipeline_tag": "",
"library_name": "transformers"
}
Source payload excerpt (from Hugging Face API)
{
"_id": "682e89f650671dc82681823c",
"id": "Mungert/typhoon-ocr-7b-GGUF",
"modelId": "Mungert/typhoon-ocr-7b-GGUF",
"sha": "0238e98ead7a4e3b5aa347f5d07943987af39c2c",
"createdAt": "2025-05-22T02:20:38.000Z",
"lastModified": "2025-09-24T15:42:31.000Z",
"author": "Mungert",
"downloads": 301,
"likes": 0,
"gated": false,
"private": false,
"pipeline_tag": "",
"library_name": "transformers",
"siblings_count": 30
}