davidau/qwen3-vl-12b-thinking-brainstorm20x-neo-max-gguf IQ4_XS GGUF - Free GGUF Download is indexed on GraySoft with repository links, GGUF quant files, and Hugging Face metadata. This page helps you pick a local model for guIDE or other runtimes. See related models in the same shard below.
davidau/qwen3-vl-12b-thinking-brainstorm20x-neo-max-gguf overview
--- Meet Qwen3-VL — the most powerful vision-language model in the Qwen series to date. This generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities. Available in Dense and MoE architectures that scale from edge to cloud, with Instruct and reasoning‑enhanced Thinking editions for flexible, on‑demand deployment. #### Key Enhancements: Visual Agent: Operates PC/mobile GUIs—recognizes elements, understands functions, invokes tools, completes tasks. Visual Coding Boost: Generates Draw.io/HTML/CSS/JS from images/videos. Advanced Spatial Perception: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI. Long Context & Video Understanding: Native 256K context, expandable to 1M; handles books and hours-long video with full recall and second-level indexing. Enhanced Multimodal Reasoning: Excels in STEM/Math—causal analysis and logical, evidence-based answers. Upgraded Visual Recognition: Broader, higher-quality pretraining is able to “recognize everything”—celebrities, anime, products, landmarks, flora/fauna, etc. Expanded OCR: Supports 32 languages (up from 19); robust in low light, blur, and tilt; better with rare/ancient characters and jargon; improved long-document structure parsing. Text Understanding on par with pure LLMs: Seamless text–vision fusion for lossless, unified comprehension. #### Model Architecture Updates: 1. Interleaved-MRoPE: Full‑frequency allocation over time, width, and height via robust positional embeddings, enhancing long‑horizon video reasoning. 2. DeepStack: Fuses multi‑level ViT features to capture fine‑grained details and sharpen image–text alignment. 3. Text–Timestamp Alignment: Moves beyond T‑RoPE to precise, timestamp‑grounded event localization for stronger video temporal modeling. This is the weight repository for Qwen3-VL-8B-Thinking. ---

Repository Files & Downloads
| File | Type | Quantization | Size | Link |
|---|---|---|---|---|
| Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-IQ2_M.gguf | GGUF | IQ2_M | 4.76 GB | Download |
| Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-IQ3_M.gguf | GGUF | IQ3_M | 5.84 GB | Download |
| Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-IQ4_XS.gguf | GGUF | IQ4_XS | 6.76 GB | Download |
| Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-Q4_K_M.gguf | GGUF | Q4_K_M | 7.41 GB | Download |
| Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-Q4_K_S.gguf | GGUF | Q4_K_S | 7.09 GB | Download |
| Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-Q5_K_M.gguf | GGUF | Q5_K_M | 8.54 GB | Download |
| Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-Q5_K_S.gguf | GGUF | Q5_K_S | 8.36 GB | Download |
| Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-Q6_K.gguf | GGUF | Q6_K | 9.75 GB | Download |
| Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-Q8_0.gguf | GGUF | — | 12.28 GB | Download |
| mmproj-Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-BF16.gguf | GGUF | BF16 | 1.08 GB | Download |
| mmproj-Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-F16.gguf | GGUF | F16 | 1.08 GB | Download |
| mmproj-Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-F32.gguf | GGUF | F32 | 2.15 GB | Download |
| mmproj-Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-D_AU-Q8_0.gguf | GGUF | — | 717.44 MB | Download |
Model Details Live
Metadata Inspector
Normalized metadata (stored in metadata_json)
{
"metadata": {},
"card_data": {
"license": "apache-2.0",
"base_model": [
"DavidAU/Qwen3-VL-12B-Thinking-Brainstorm20x"
],
"language": [
"en"
],
"pipeline_tag": "image-text-to-text",
"tags": [
"programming",
"code generation",
"images",
"image to text",
"qwen3_vl_text",
"Qwen3VLForConditionalGeneration",
"video",
"code",
"coding",
"coder",
"chat",
"code",
"chat",
"brainstorm",
"qwen",
"qwen3",
"qwencoder",
"NEO",
"NEO Imatrix",
"brainstorm 20x",
"all uses cases",
"creative",
"ggufs"
],
"frontmatter": {
"license": "apache-2.0",
"base_model": [
"DavidAU/Qwen3-VL-12B-Thinking-Brainstorm20x"
],
"language": [
"en"
],
"pipeline_tag": "image-text-to-text",
"tags": [
"programming",
"code generation",
"images",
"image to text",
"qwen3_vl_text",
"Qwen3VLForConditionalGeneration",
"video",
"code",
"coding",
"coder",
"chat",
"code",
"chat",
"brainstorm",
"qwen",
"qwen3",
"qwencoder",
"NEO",
"NEO Imatrix",
"brainstorm 20x",
"all uses cases",
"creative",
"ggufs"
]
},
"hero_image_url": "qwen-vl.gif",
"summary": "--- Meet Qwen3-VL — the most powerful vision-language model in the Qwen series to date. This generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities. Available in Dense and MoE architectures that scale from edge to cloud, with Instruct and reasoning‑enhanced Thinking editions for flexible, on‑demand deployment. #### Key Enhancements: * **Visual Agent**: Operates PC/mobile GUIs—recognizes elements, understands functions, invokes tools, completes tasks. * **Visual Coding Boost**: Generates Draw.io/HTML/CSS/JS from images/videos. * **Advanced Spatial Perception**: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI. * **Long Context & Video Understanding**: Native 256K context, expandable to 1M; handles books and hours-long video with full recall and second-level indexing. * **Enhanced Multimodal Reasoning**: Excels in STEM/Math—causal analysis and logical, evidence-based answers. * **Upgraded Visual Recognition**: Broader, higher-quality pretraining is able to “recognize everything”—celebrities, anime, products, landmarks, flora/fauna, etc. * **Expanded OCR**: Supports 32 languages (up from 19); robust in low light, blur, and tilt; better with rare/ancient characters and jargon; improved long-document structure parsing. * **Text Understanding on par with pure LLMs**: Seamless text–vision fusion for lossless, unified comprehension. #### Model Architecture Updates: 1. **Interleaved-MRoPE**: Full‑frequency allocation over time, width, and height via robust positional embeddings, enhancing long‑horizon video reasoning. 2. **DeepStack**: Fuses multi‑level ViT features to capture fine‑grained details and sharpen image–text alignment. 3. **Text–Timestamp Alignment:** Moves beyond T‑RoPE to precise, timestamp‑grounded event localization for stronger video temporal modeling. This is the weight repository for Qwen3-VL-8B-Thinking. ---",
"quick_links": [],
"benchmark_table_html": "",
"readme_markdown": "---\nlicense: apache-2.0\nbase_model:\n- DavidAU/Qwen3-VL-12B-Thinking-Brainstorm20x\nlanguage:\n- en\npipeline_tag: image-text-to-text\ntags:\n- programming\n- code generation\n- images\n- image to text\n- qwen3_vl_text\n- Qwen3VLForConditionalGeneration\n- video\n- code\n- coding\n- coder\n- chat\n- code\n- chat\n- brainstorm\n- qwen\n- qwen3\n- qwencoder\n- NEO\n- NEO Imatrix\n- brainstorm 20x\n- all uses cases\n- creative\n- ggufs\n---\n\n[examples to be added] [BENCHMARKS coming soon.]\n\n<h2>Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-MAX-GGUF</h2>\n\n<img src=\"qwen-vl.gif\" style=\"float:right; width:300px; height:300px; padding:10px;\">\n\nThis model contains the full source of the original \"Qwen3-VL-Thinking-8B\" coupled with Brainstorm 20x adapter (by DavidAU)\nwith augmented GGUF quants (NEO Imatrix) with MAX 16 bit output tensor.\n\nThis is the full image/text/multi-modal model AND fully tested.\n\nBrainstorm 20x will augment text generation as well as \"image\" description and in many cases raises the raw benchmarks of the model (which are already\nvery impressive (see below) ) too.\n\nBrainstorm also augments \"thinking\" too.\n\nAddition of the Brainstorm adapter has altered the model from 8B to 12B (now with 55 layers and 608 tensors).\n\nGGUFs further enhanced with NEO IMATRIX dataset, and MAX output tensor (makes up 10-20% of model output quality) set at 16 bits.\n\nNote that Q8_0 will only have MAX output tensor at 16 bits, as Imatrix has no effect on this quant.\n\n<B><font color=\"red\">IMPORTANT:</font> - Looping?</B>\n\nThis model tends to loop sometimes, if this happens set temp to \"1\" (or higher) and rep pen to \"1.1\" . The org model has the same issue.\nIf you have the option, set \"presence penalty\" to 2.0 [as per Qwen's own suggestions]\n\n<U>IMPORTANT => GGUF QUANTS:</u>\n\nYou need both the GGUF quant(s) AND the special \"mmproj\" gguf quant (ONE: Q8,F16,BF16 or F32) to use all functions with this model.\n\nSave these to the SAME folder.\n\nIn LMStudio, the app will auto-detect the \"mmproj\" file, and new options will be available.\n\nFor Koldboldcpp you have to load the GGUF and the \"mmproj\" file [this is in two separate sections in the loader].\n\n---\n\n<h2>MODEL DETAILS:</h2>\n\n(Quants, Benchmarks, Brainstorm details, org model details from Qwen, and then help section)\n\n---\n\nThis model requires:\n- Jinja (embedded) or CHATML template\n- Max context of 256k.\n\nSettings used for testing (suggested):\n- Temp .3 to .7 (but .8 to 1.5 for creative)\n- Rep pen 1.05 to 1.1\n- Topp .8 , minp .05\n- Topk 20\n- Min context of 8k for thinking / output.\n- No system prompt.\n\nThis model will respond well to both detailed instructions and step by step refinement and additions to code.\n\nLikewise for creative use cases.\n\nAs this is an instruct model, it will also benefit from a detailed system prompt too.\n\nFor simpler coding problems, lower quants will work well; but for complex/multi-step problem solving suggest Q6 or Q8.\n\n---\n\nBENCHMARKS by Nightmedia (also makes MLX quants too)\n\nhttps://huggingface.co/nightmedia/\n\n- coming soon -\n\n---\n\n\n\n---\n\n<H2>What is Brainstorm?</H2>\n\n---\n\n<B>Brainstorm 20x</B>\n\nThe BRAINSTORM process was developed by David_AU.\n\nSome of the core principals behind this process are discussed in this <a href=\"https://arxiv.org/pdf/2401.02415\"> \nscientific paper : Progressive LLaMA with Block Expansion </a>. \n\nHowever I went in a completely different direction from what was outlined in this paper.\n\nWhat is \"Brainstorm\" ?\n\nThe reasoning center of an LLM is taken apart, reassembled, and expanded.\n\nIn this case for this model: 20 times\n\nThen these centers are individually calibrated. These \"centers\" also interact with each other. \nThis introduces subtle changes into the reasoning process. \nThe calibrations further adjust - dial up or down - these \"changes\" further. \nThe number of centers (5x,10x etc) allow more \"tuning points\" to further customize how the model reasons so to speak.\n\nThe core aim of this process is to increase the model's detail, concept and connection to the \"world\", \ngeneral concept connections, prose quality and prose length without affecting instruction following. \n\nThis will also enhance any creative use case(s) of any kind, including \"brainstorming\", creative art form(s) and like case uses.\n\nHere are some of the enhancements this process brings to the model's performance:\n\n- Prose generation seems more focused on the moment to moment. \n- Sometimes there will be \"preamble\" and/or foreshadowing present.\n- Fewer or no \"cliches\"\n- Better overall prose and/or more complex / nuanced prose.\n- A greater sense of nuance on all levels.\n- Coherence is stronger.\n- Description is more detailed, and connected closer to the content.\n- Simile and Metaphors are stronger and better connected to the prose, story, and character.\n- Sense of \"there\" / in the moment is enhanced.\n- Details are more vivid, and there are more of them.\n- Prose generation length can be long to extreme.\n- Emotional engagement is stronger.\n- The model will take FEWER liberties vs a normal model: It will follow directives more closely but will \"guess\" less.\n- The MORE instructions and/or details you provide the more strongly the model will respond.\n- Depending on the model \"voice\" may be more \"human\" vs original model's \"voice\".\n\nOther \"lab\" observations:\n\n- This process does not, in my opinion, make the model 5x or 10x \"smarter\" - if only that was true! \n- However, a change in \"IQ\" was not an issue / a priority, and was not tested or calibrated for so to speak.\n- From lab testing it seems to ponder, and consider more carefully roughly speaking.\n- You could say this process sharpens the model's focus on it's task(s) at a deeper level.\n\nThe process to modify the model occurs at the root level - source files level. The model can quanted as a GGUF, EXL2, AWQ etc etc.\n\n---\n\n# Qwen3-VL-8B-Thinking\n\n---\n\n\nMeet Qwen3-VL — the most powerful vision-language model in the Qwen series to date.\n\nThis generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities.\n\nAvailable in Dense and MoE architectures that scale from edge to cloud, with Instruct and reasoning‑enhanced Thinking editions for flexible, on‑demand deployment.\n\n\n#### Key Enhancements:\n\n* **Visual Agent**: Operates PC/mobile GUIs—recognizes elements, understands functions, invokes tools, completes tasks.\n\n* **Visual Coding Boost**: Generates Draw.io/HTML/CSS/JS from images/videos.\n\n* **Advanced Spatial Perception**: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI.\n\n* **Long Context & Video Understanding**: Native 256K context, expandable to 1M; handles books and hours-long video with full recall and second-level indexing.\n\n* **Enhanced Multimodal Reasoning**: Excels in STEM/Math—causal analysis and logical, evidence-based answers.\n\n* **Upgraded Visual Recognition**: Broader, higher-quality pretraining is able to “recognize everything”—celebrities, anime, products, landmarks, flora/fauna, etc.\n\n* **Expanded OCR**: Supports 32 languages (up from 19); robust in low light, blur, and tilt; better with rare/ancient characters and jargon; improved long-document structure parsing.\n\n* **Text Understanding on par with pure LLMs**: Seamless text–vision fusion for lossless, unified comprehension.\n\n\n#### Model Architecture Updates:\n\n<p align=\"center\">\n <img src=\"https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-VL/qwen3vl_arc.jpg\" width=\"80%\"/>\n<p>\n\n\n1. **Interleaved-MRoPE**: Full‑frequency allocation over time, width, and height via robust positional embeddings, enhancing long‑horizon video reasoning.\n\n2. **DeepStack**: Fuses multi‑level ViT features to capture fine‑grained details and sharpen image–text alignment.\n\n3. **Text–Timestamp Alignment:** Moves beyond T‑RoPE to precise, timestamp‑grounded event localization for stronger video temporal modeling.\n\n\nThis is the weight repository for Qwen3-VL-8B-Thinking.\n\n\n---\n\n## Model Performance\n\n**Multimodal performance**\n\n\n\n**Pure text performance**\n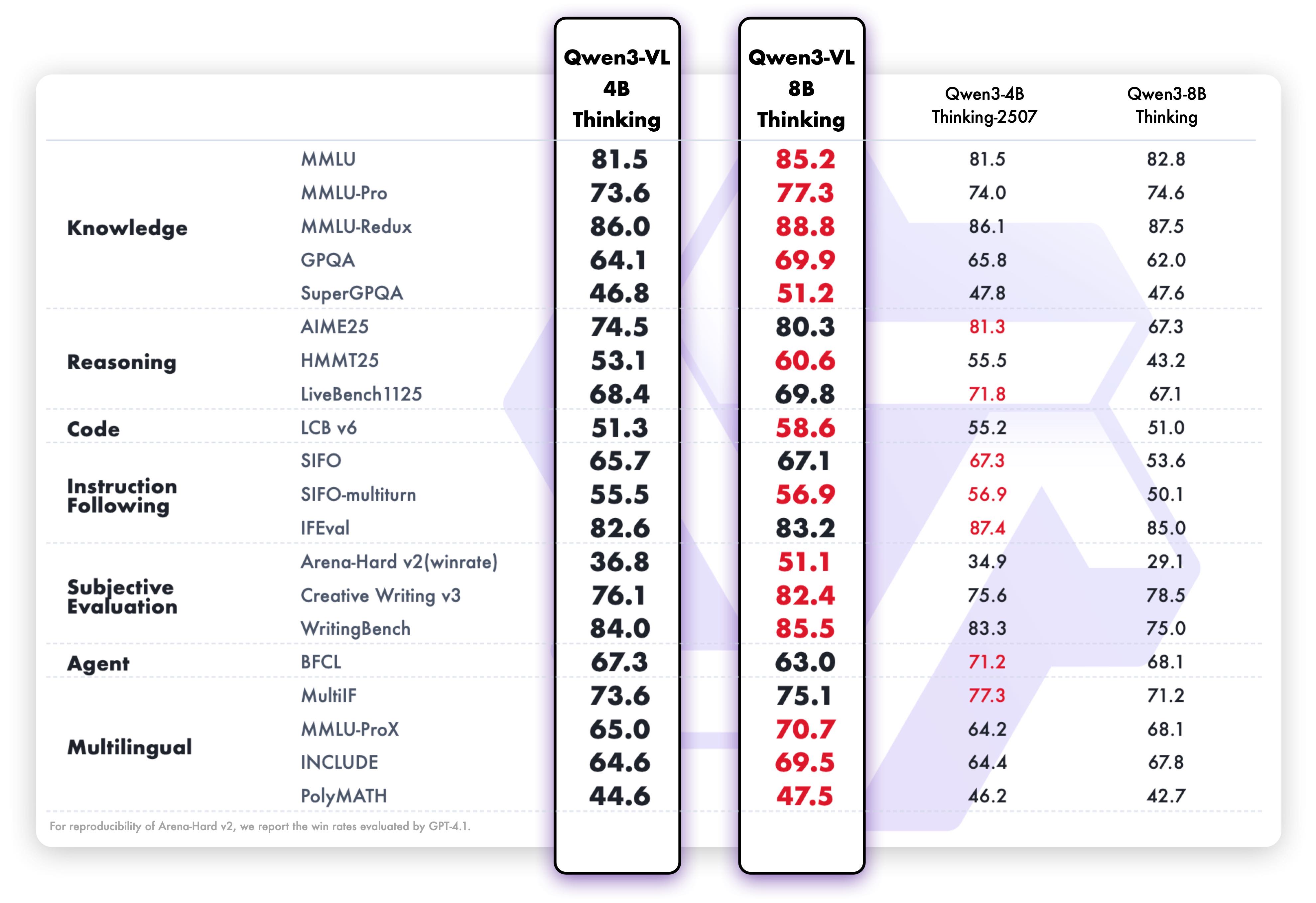\n\n## Quickstart\n\nBelow, we provide simple examples to show how to use Qwen3-VL with 🤖 ModelScope and 🤗 Transformers.\n\nThe code of Qwen3-VL has been in the latest Hugging face transformers and we advise you to build from source with command:\n```\npip install git+https://github.com/huggingface/transformers\n# pip install transformers==4.57.0 # currently, V4.57.0 is not released\n```\n\n### Using 🤗 Transformers to Chat\n\nHere we show a code snippet to show you how to use the chat model with `transformers`:\n\n```python\nfrom transformers import Qwen3VLForConditionalGeneration, AutoProcessor\n\n# default: Load the model on the available device(s)\nmodel = Qwen3VLForConditionalGeneration.from_pretrained(\n \"Qwen/Qwen3-VL-8B-Thinking\", dtype=\"auto\", device_map=\"auto\"\n)\n\n# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.\n# model = Qwen3VLForConditionalGeneration.from_pretrained(\n# \"Qwen/Qwen3-VL-8B-Thinking\",\n# dtype=torch.bfloat16,\n# attn_implementation=\"flash_attention_2\",\n# device_map=\"auto\",\n# )\n\nprocessor = AutoProcessor.from_pretrained(\"Qwen/Qwen3-VL-8B-Thinking\")\n\nmessages = [\n {\n \"role\": \"user\",\n \"content\": [\n {\n \"type\": \"image\",\n \"image\": \"https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg\",\n },\n {\"type\": \"text\", \"text\": \"Describe this image.\"},\n ],\n }\n]\n\n# Preparation for inference\ninputs = processor.apply_chat_template(\n messages,\n tokenize=True,\n add_generation_prompt=True,\n return_dict=True,\n return_tensors=\"pt\"\n)\ninputs = inputs.to(model.device)\n\n# Inference: Generation of the output\ngenerated_ids = model.generate(**inputs, max_new_tokens=128)\ngenerated_ids_trimmed = [\n out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)\n]\noutput_text = processor.batch_decode(\n generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False\n)\nprint(output_text)\n```\n\n### Generation Hyperparameters\n#### VL\n```bash\nexport greedy='false'\nexport top_p=0.95\nexport top_k=20\nexport repetition_penalty=1.0\nexport presence_penalty=0.0\nexport temperature=1.0\nexport out_seq_length=40960\n```\n\n#### Text\n```bash\nexport greedy='false'\nexport top_p=0.95\nexport top_k=20\nexport repetition_penalty=1.0\nexport presence_penalty=1.5\nexport temperature=1.0\nexport out_seq_length=32768 (for aime, lcb, and gpqa, it is recommended to set to 81920)\n```\n\n\n\n---\n\n<H2>Help, Adjustments, Samplers, Parameters and More</H2>\n\n---\n\n<B>CHANGE THE NUMBER OF ACTIVE EXPERTS:</B>\n\nSee this document:\n\nhttps://huggingface.co/DavidAU/How-To-Set-and-Manage-MOE-Mix-of-Experts-Model-Activation-of-Experts\n\n<B>Settings: CHAT / ROLEPLAY and/or SMOOTHER operation of this model:</B>\n\nIn \"KoboldCpp\" or \"oobabooga/text-generation-webui\" or \"Silly Tavern\" ;\n\nSet the \"Smoothing_factor\" to 1.5 \n\n: in KoboldCpp -> Settings->Samplers->Advanced-> \"Smooth_F\"\n\n: in text-generation-webui -> parameters -> lower right.\n\n: In Silly Tavern this is called: \"Smoothing\"\n\n\nNOTE: For \"text-generation-webui\" \n\n-> if using GGUFs you need to use \"llama_HF\" (which involves downloading some config files from the SOURCE version of this model)\n\nSource versions (and config files) of my models are here:\n\nhttps://huggingface.co/collections/DavidAU/d-au-source-files-for-gguf-exl2-awq-gptq-hqq-etc-etc-66b55cb8ba25f914cbf210be\n\nOTHER OPTIONS:\n\n- Increase rep pen to 1.1 to 1.15 (you don't need to do this if you use \"smoothing_factor\")\n\n- If the interface/program you are using to run AI MODELS supports \"Quadratic Sampling\" (\"smoothing\") just make the adjustment as noted.\n\n<B>Highest Quality Settings / Optimal Operation Guide / Parameters and Samplers</B>\n\nThis a \"Class 1\" model:\n\nFor all settings used for this model (including specifics for its \"class\"), including example generation(s) and for advanced settings guide (which many times addresses any model issue(s)), including methods to improve model performance for all use case(s) as well as chat, roleplay and other use case(s) please see:\n\n[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]\n\nYou can see all parameters used for generation, in addition to advanced parameters and samplers to get the most out of this model here:\n\n[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]\n\n",
"related_quantizations": []
},
"tags": [
"gguf",
"programming",
"code generation",
"images",
"image to text",
"qwen3_vl_text",
"Qwen3VLForConditionalGeneration",
"video",
"code",
"coding",
"coder",
"chat",
"brainstorm",
"qwen",
"qwen3",
"qwencoder",
"NEO",
"NEO Imatrix",
"brainstorm 20x",
"all uses cases",
"creative",
"ggufs",
"image-text-to-text",
"en",
"arxiv:2401.02415",
"base_model:DavidAU/Qwen3-VL-12B-Thinking-Brainstorm20x",
"base_model:quantized:DavidAU/Qwen3-VL-12B-Thinking-Brainstorm20x",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
],
"likes": 3,
"downloads": 543,
"gated": false,
"private": false,
"last_modified": "2025-11-10T10:58:21.000Z",
"created_at": "2025-11-06T23:43:58.000Z",
"pipeline_tag": "image-text-to-text",
"library_name": ""
}
Source payload excerpt (from Hugging Face API)
{
"_id": "690d32be9f252aa8979d6c2c",
"id": "DavidAU/Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-MAX-GGUF",
"modelId": "DavidAU/Qwen3-VL-12B-Thinking-Brainstorm20x-NEO-MAX-GGUF",
"sha": "8826951045bb3acf5ce694898b1d619e79a2fef8",
"createdAt": "2025-11-06T23:43:58.000Z",
"lastModified": "2025-11-10T10:58:21.000Z",
"author": "DavidAU",
"downloads": 543,
"likes": 3,
"gated": false,
"private": false,
"pipeline_tag": "image-text-to-text",
"library_name": "",
"siblings_count": 16
}